
티스토리 뷰
[400분이 걸리는 10만 개의 알림 요청 시간을 줄여보자] 2. @Async와 Executor를 사용해 비동기로 이사가기
Gray__ 2024. 2. 20. 16:50(이 글은 외로운 우테코 5기 취준생 “김동욱”, “이건회” aka “그레이”, “하마드”가 작성했습니다.)
동기적 알림 처리를 비동기로 수정
@Component
@RequiredArgsConstructor
public class NotificationEventListener {
private final NotificationService notificationService;
@EventListener
@Async
public void handleNotificationEvents(NotificationEvents notificationEvents) {
for (NotificationEvent event : notificationEvents.getNotificationEvents()) {
notificationService.sendNotification(event.getDeviceToken(), event.getTitle(), event.getBody());
}
}
}일단 먼저 저번 글에서 언급했던 바보같은 코드를 하나 수정했다.
알림 처리 이벤트를 비동기로 변경했지만, 결국 하나의 비동기 스레드가 모든 알림을 일괄적으로 보내는 로직이었다.
@Scheduled(cron = "0 0 7 * * *")
public void sendWaterNotification() {
List<PetPlant> petPlants = petPlantRepository.findAllByWaterNotification(LocalDate.now());
log.info("[" + LocalDate.now() + " 물주기] " + "전체 알림: " + petPlants.size() + "개");
petPlants.forEach(this::sendNotification);
}
private void sendNotification(PetPlant petPlant) {
NotificationEvent.builder()
.title(petPlant.getNickname())
.body("물을 줄 시간이에요!")
.deviceToken(petPlant.getMember().getDeviceToken())
.build();
publisher.publishEvent(petPlant);
}@Component
@RequiredArgsConstructor
@Slf4j
public class NotificationEventListener {
private final NotificationService notificationService;
@EventListener
@Async
public void handleNotificationEvent(NotificationEvent event) {
notificationService.sendNotification(event.getDeviceToken(), event.getTitle(), event.getBody());
}
}
다음과 같이 각각의 알림 이벤트를 개별 비동기 스레드가 보내는 로직으로 변환했다.
이 타이밍에 성능체크를 한번 해 보겠다.

단순 기본 @Async 처리만 해도 처리 시간이 상당히 빨리지는 것을 볼 수 있었다.
400분이 걸렸던 10만개 알림 전송 시간이 약 120분, 무려 280분이 단축됐다.
더 빠르게 할 수는 없을까?
하지만 10만개 알림이 120분 걸린다는 것은 여전히 사용자에게 크리티컬하다. 우리의 목표는 최대한 07시에 가깝게 알림을 보내는 것이기 때문이다. 더 빠르게 만들 수는 없을까?
성능 지표를 보던 중 의아한 부분이 생겼다. 비동기 처리를 했다면 알림 이벤트마다 각자 스레드가 생겨서 알림을 처리할 테고, 그만큼 CPU 사용량도 높아져야 할텐데, 왜 CPU 사용량은 평균적으로 20%에 머물러 있을까?
그렇다면 결국 몇 개의 스레드가 비동기 처리를 위해 사용되고 있는지 파악해야 할 것이다.
Thread dump를 통해 현재 jvm에서 구동되고 있는 스레드 목록을 확인해보겠다.
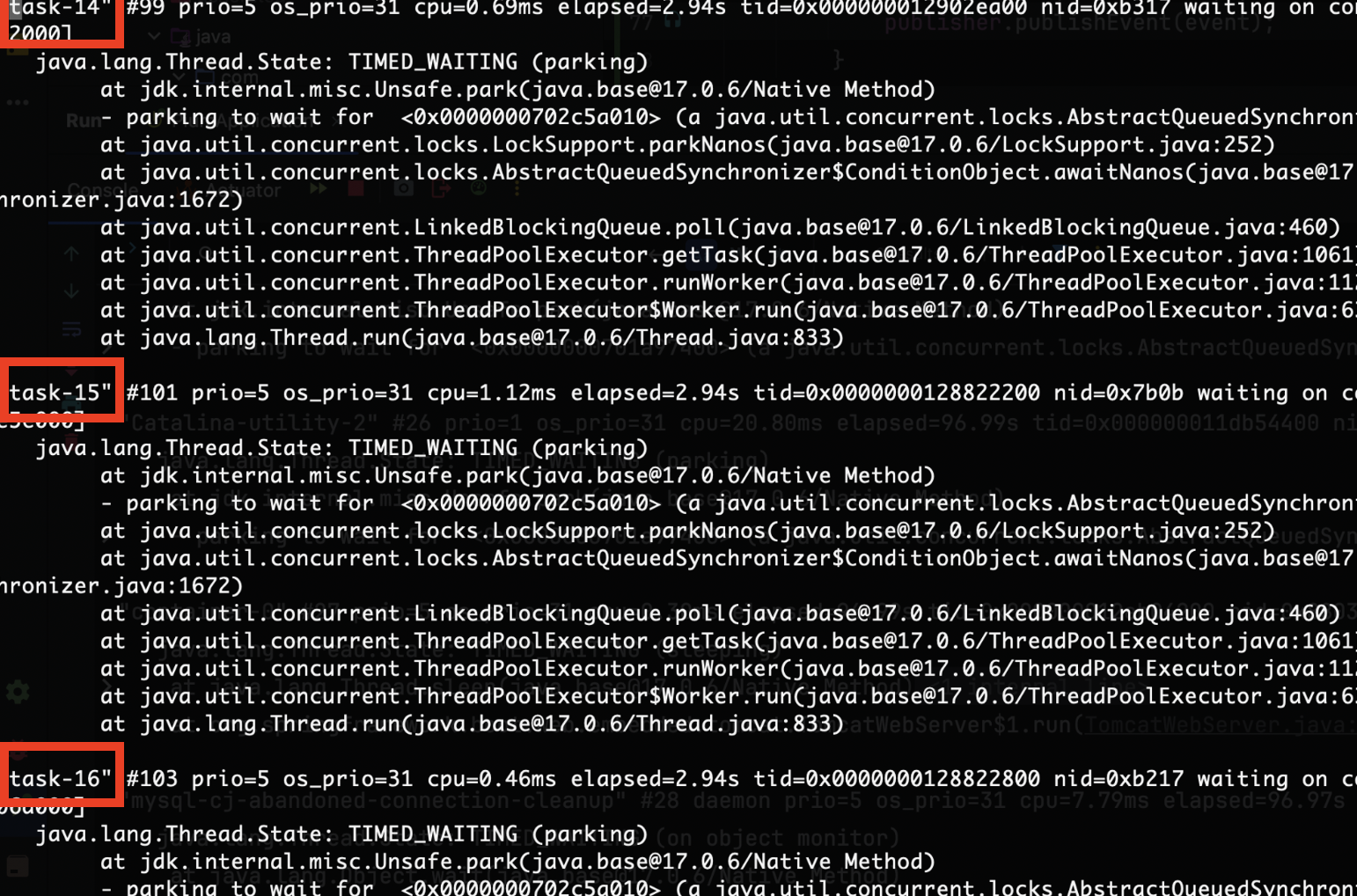
“task-**” 이라고 이름붙여진 스레드가 비동기 로직을 처리하는 스레드다. 이 스레드가 총 몇 개 있는지 확인해보니 8개만 존재하고 있었다. 왜 8개만 쓰고 있었을까?
스프링 @Async의 동작 방식 파악
스프링에서 제공하는 @Async 어노테이션은 어떤 방식으로 동작할까?
@Async 는 스프링의 AOP에 의해서 동작한다. 해당 어노테이션이 선언된 메서드는 비동기 메서드로 동작하게 된다.
조금 더 깊게 들어가보면 AsyncExecutionAspectSupport 클래스의 doSubmit 메서드를 통해 최종적으로 실행되는데, 메서드의 리턴 타입(void, Future, ComparableFuture, ListenableFuture)에 따라서 다르게 동작한다.
protected Object doSubmit(Callable<Object> task, AsyncTaskExecutor executor, Class<?> returnType) {
if (CompletableFuture.class.isAssignableFrom(returnType)) {
return executor.submitCompletable(task);
}
else if (org.springframework.util.concurrent.ListenableFuture.class.isAssignableFrom(returnType)) {
return ((org.springframework.core.task.AsyncListenableTaskExecutor) executor).submitListenable(task);
}
else if (Future.class.isAssignableFrom(returnType)) {
return executor.submit(task);
}
else if (void.class == returnType) {
executor.submit(task);
return null;
}
else {
throw new IllegalArgumentException(
"Invalid return type for async method (only Future and void supported): " + returnType);
}
}
그렇다면 별도의 스레드 풀을 설정하지 않은 @Async 는 어떤 스레드 풀을 기준으로 사용할까?
해당 어노테이션을 선언한 메서드는 비동기로 실행될 때 새로운 스레드가 생성된다.
별도의 스레드 풀 설정을 하지 않는다면 스프링 부트에서 TaskExecutionAutoConfiguration 설정을 읽어 비동기 스레드를 생성한다.
해당 클래스를 보면 TaskExecutionProperties 클래스에서 설정 값을 읽어온다는 것을 확인할 수 있고 thread prefix와 coreSize 값을 확인할 수 있다. 앞서 스레드 덤프를 통해 확인한 task-n 이름의 스레드들이 이 설정을 통해 생성되는 스레드임을 확인할 수 있다.

여기서 주의해서 볼 점은 queueCapacity와 maxSize이다. 두 값 모두 Integer 최대값으로 설정되어 있는데 maxSize는 스레드를 할당 받기 위해 기다리는 대기 큐 크기가 queueCapacity를 넘었을 때 최대로 생성되는 스레드 크기이다.
위 테스트에서 8개의 스레드만 사용된 이유는 바로 이 설정 때문이다. coreSize가 8이고 queueCapacity가 21억쯤 되기 때문에 10만개 알림으로는 coreSize 이상의 스레드를 생성할 수 없다.
그러므로 현재 서버 자원으로 가용할 수 있는 스레드를 최대한 활용하여 처리 시간을 단축하는 것이 필요하다.
ThreadPoolTaskExecutor를 활용해 비동기 스레드 개수를 커스텀하자
비동기 스레드를 8개만 쓴다고 해서 너무 낙심할 필요는 없다. 스프링은 친절하게도 우리에게 비동기 처리 스레드 갯수를 조정하는 기능을 제공하고 있다.

(사진출처 : https://docs.spring.io/)
스프링에서는 AsyncConfigurer 를 통해 비동기 메소드 호출 처리시 사용되는 Executor 인스턴스를 커스터마이징하는 설정자를 제공한다. 사용법이 친절하게 공식 문서에 기술되어 있다. @EnableAsync 어노테이션 처리된 @Configuration 클래스로 이 메소드를 구현하면 된다.

아까 보았던 @TaskExecutionAutoConfiguration 에서 위와 같은 방식으로 이것저것 지정한 부분들을 우리가 직접 커스텀할 수 있다.
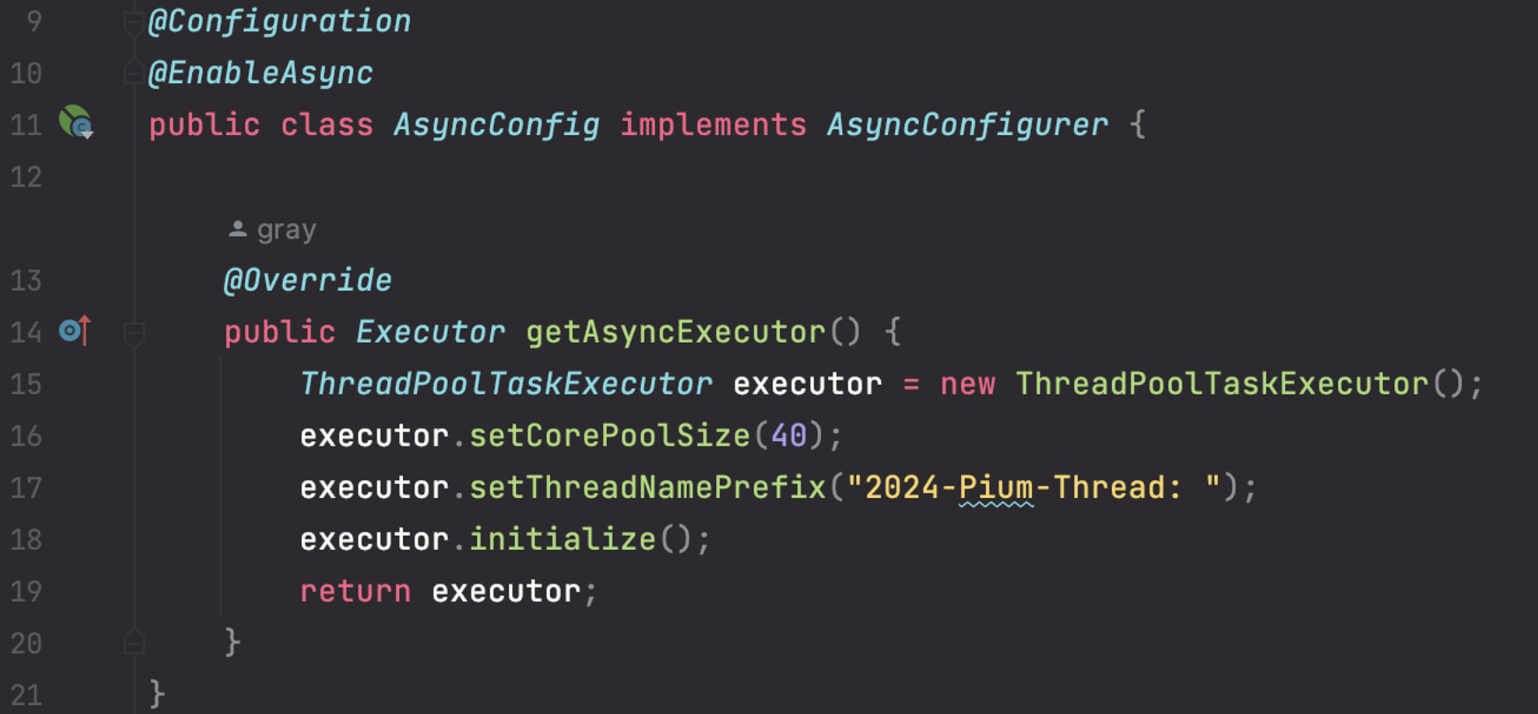
만약, 기능 당 비동기 스레드 설정을 여러개 구분하고 싶으면 AsyncConfigurer 를 구현하는 것이 아닌, 각각을 @Bean("customThreadPool") 으로 등록하고 @Async("customThreadPool") 비동기 어노테이션을 설정할 때 빈 이름으로 구분하여 사용해야 한다.
Executor 는 기본적으로 corePoolSize 만큼 스레드를 생성해 동작하고 그 이상의 요청은 대기 큐에 보낸다. 이후 대기 큐가 꽉 차게되면 큐 이상의 요청이 들어올때 추가적으로 스레드를 할당하는 구조다. 이 때 maxPoolSize 를 설정한 만큼만 추가로 스레드를 할당할 수 있다.
정리하자면 비동기 요청이 들어오면
- corePoolSize 만큼 ThreadPool에 스레드가 있는지 확인
- corePoolSize 보다 적으면 새로운 스레드 할당
- corePoolSize 만큼 존재하면 추가 할당하지 않음
- corePoolSize의 모든 스레드가 활동중이면 대기 큐에 할당
- 대기큐가 꽉 차면 새로운 스레드 1개 할당
- 5번이 반복되어 maxPoolSize에 도달하면 더이상 스레드 할당 x
- maxPoolSize 만큼 차고 대기 큐도 찬 상태에서 추가 요청이 들어오면 → 예외를 터트림(이는 다른 정책으로 수정 가능)
우리 서비스의 경우는 10만개의 알림이 동시에 발생한다고 가정하기에, queueCapacity와 maxPoolSize 를 사용해 스레드 갯수를 유동적으로 조정하는 방법은 옳지 않다고 판단했다. 또 우리의 알림 서비스의 경우 그날 물주기 사용자에게 대략 몇 건의 알림이 발생하는지를 예측하기 쉬운 특성이 있었다.
n개의 스레드 갯수를 고정하여 항시 가용 가능한 최대 스레드를 풀로 사용, 최대한 빠르게 처리하도록 하는 방법이 더 나은 방향이라고 판단했다.
따라서 큐 사이즈를 기본 설정인 Integer.MAX_VALUE 로 유지하고, corePoolSize 만을 조절하여 최적의 스레드 갯수를 지정하고자 했다.
스레드를 늘려가며 최적의 스레드 갯수를 찾아보자
그렇다면 비동기 스레드를 몇 개나 사용해야 잘 썼다고 소문이 날까? 직접 테스트를 해봐야 알 수 있을 것이다.
테스트를 해보려면 어느 부분을 테스트해야할지 지정해야할 것이다. 우리는 비동기 스레드 갯수를 10씩 늘려가며, CPU 사용량과 메모리 사용량, 그리고 총 처리 시간을 기록하기로 했다.
또한, 어떤 지표로 최적의 스레드 갯수임을 파악하고 지정해야 할까?
먼저 CPU의 경우 대부분의 대용량서비스에서 50% 의 사용량을 스케일 아웃 임계점으로 삼고 있음을 레퍼런스 삼았다(카카오 알림개선기 잘봤습니다). 그러나…우리는 CPU가 50% 이상 튄다고 해서 덜컥 서버를 구매할 돈이 없다(백ㅜ수임ㅠㅜ). 그래서 임계치를 65% 정도로 살짝 올려주는 걸로 타협을 봤다(살짝 맞나…?).
메모리의 경우, 이후 테스트 결과에서 확인하겠지만 스레드 갯수에 관계없이 일정한 데이터를 끌고오고, 같은 프로세스 내부에서 실행하므로 모든 테스트 결과에서 50% 이하의 메모리 사용량을 꾸준히 유지하고 있었다.
마지막으로 처리 시간. 우리는 10개씩 스레드를 늘려가며 테스트를 하기로 했는데 이 때 스레드를 추가해도 유의미하게 처리 시간이 빨라지지 않는 지점을 찾기로 했다. 즉 불필요한 컨텍스트 스위칭 비용을 줄이기 위해서다.
자.. 테스트 드가자~

AWS CloudWatch를 활용해 매트릭으로 확인한 결과를 표로 정리했다.
확실히 스레드를 늘릴 수록 유의미하게 시간이 줄어든다.
맨 아래 10만개 전송 테스트 결과를 확인해보면, 스레드가 30개에서 40개로 늘어날 때 처리시간이 3분 30초 이상 줄어들었고, 40개에서 50개로 늘어날 때는 1분 10초 가량 줄어들었다.
설정한 CPU 임계치가 65% 였기에 평균 62.6%를 사용하는 50개가 최대라고 판단했고, 그 이상을 테스트하지는 않기로 했다. 이후에 심심해서 한번 스레드 100개를 만들어 보냈을 때는 오히려 처리 시간이 늘어났다. 스레드 수가 많아지고 CPU가 효율적으로 처리할 수 있는 스레드 임계치를 넘어감에 따라 컨텍스트 비용이 증가하기 때문에 처리 시간이 늘어났을 것이다.
문제는 CPU 사용량이었기에, 우리는 50개 스레드와 이에 근접한 40개 스레드 중 어떤 것을 선택할지 고민했다.
그런데, 문제가 있었다. 테스트를 시작한 직후, 초반 간헐적으로 CPU 사용량이 99.9%로 튀어오르는 일이 계속 발생했다.
따라서 위에서 결정한 CPU 최대 사용량은 모두 99.9% 였기에, 최대 사용량으로 임계치를 설정한 우리는 골머리를 겪었다.
이 문제를 어떻게 해결했을까? 다음 포스팅에 상세히 기록하도록 하겠다.
하여튼 결론적으로 10만 개의 알림을 40개 스레드를 사용했을 때 12분 36초, 50개 스레드를 사용했을 때 11분 25초를 기록했고, 기존 400분의 알림을 10분대 초반까지 줄일 수 있었다.
RestTemplate의 허점을 파악해 완전한 비동기 처리로 전환하자
여기서 더 줄일 수 있는 방법은 없을까? 그래도 10분 안으로는 줄이고 싶었다. 방법을 찾던 중 HTTP 요청 부분에서 문제를 하나 찾아낼 수 있었다. 우리는 Firebase 서버에 알림 HTTP 콜을 할 때 RestTemplate 을 사용하고 있었다.
하지만 RestTemplate은 Blocking 방식으로 동작하기 때문에 만약 스레드가 RestTemplate 을 이용해 HTTP 콜을 보내고 응답을 기다리는 동안 스레드는 계속 응답을 대기하고 있다. 이 경우 기다리는 시간 동안 해당 스레드는 작업을 하지 않은 채 spin-wait 상태로 CPU 사이클링에 포함되게 된다.
따라서 이를 Non-Blocking 방식으로 전환하기 위해 방법을 모색했고, 아주 쉽고 간단한 해결책을 찾아냈다.

Firebase에서는 FirebaseMessaging 객체를 이용해 알림을 전송하도록 메서드들을 제공하고 있다. FirebaseMessaging 객체를 이용해 알림을 보낼 때는 구글에서 제공하는 HttpTransport 객체를 이용해 FCM 서버와 통신한다.
이때 FirebaseMessaging 객체가 제공하는 sendAsync 메소드를 활용하면, 알림 이벤트를 구동하는 스레드와, 실제로 FCM 서버를 호출하는 스레드가 논블로킹 방식으로 분리된다. 따라서 알림 이벤트 스레드는 알림 완료를 기다릴 필요 없이 다음 알림을 바로 호출할 수 있을 거라고…생각했으나…
이 부분에서도 큰 허점이 존재한다. 자세한 내용은 다음 포스팅에…

Blocking 방식인 RestTemplate을 제거함으로써 각각의 스레드가 점유하는 CPU 수치가 0.7~1.1% 대로 줄어들었다. 그러므로 firebase Thread 40개가 추가적으로 사용되지만, 알림 요청을 보내는 jvm 스레드가 먼저 동작을 마친 후 waiting 상태로 들어가고, firebase 스레드가 따로 알림 전송을 수행하기 때문에 실제 CPU를 사용하는 수치는 이전과 비슷하거나 더 적다.
최종적으로 10만개 알림 요청의 처리시간을 약 6분 30초대까지 줄일 수 있었다.
결론
- 동기적 알림 처리 비동기로 수정함
- 기본 비동기 처리용 스레드 갯수 파악
- ThreadPoolTaskExecutor 커스텀해 비동기 스레드 갯수 조정
- 스레드 갯수를 10씩 늘려가며 최적 스레드 갯수 40 or 50으로 결정 → 10만개 알림 400분에서 10분대로 줄임
- CPU 스파이크 문제 발생, 다음 포스팅에 해결과정 쓸거임
- FCM 서버로 보내는 요청을 Blocking 방식인 RestTemplate에서 FirebaseMessaging 으로 변경
- 10만개 알림 전송 6분 30초대로 줄임
'Spring' 카테고리의 다른 글
| [400분이 걸리는 10만 개의 알림 요청 시간을 줄여보자] 4. 비동기를 더 우아하게 써볼 순 없을까? (4) | 2024.02.21 |
|---|---|
| [400분이 걸리는 10만 개의 알림 요청 시간을 줄여보자] 3. 왜 CPU 스파이크가 발생할까? JVM WarmUP으로 해결해보자 (1) | 2024.02.20 |
| [400분이 걸리는 10만 개의 알림 요청 시간을 줄여보자] 1. 우리의 알림 서비스는 왜 문제였을까? (5) | 2024.02.20 |
| [SQL] 서비스 내에서 발생하는 쿼리를 분석하고 개선하기 (4) | 2023.09.21 |
| [Spring] Logback을 이용해 운영 환경 별 로그 남기기 (2) | 2023.08.14 |
- Total
- Today
- Yesterday
- 우테코 회고
- 스프링 Logback
- 파이썬
- jpa
- 피움
- 네트워크
- CI/CD
- ZNS
- 알림개선기
- 프로젝트
- java
- Spring
- 피움 6주차 회고
- 스프링 프레임워크
- 3차 데모데이
- 알림기능개선기
- 스프링 부트
- 런칭 페스티벌
- 5주차 회고
- dm-zoned
- 회고
- 2차 데모데이
- 환경 별 로깅 전략 분리
- 8주차 회고
- 우테코
- 팀프로젝트
- 백준
- ZNS SSD
- dm-zoned 코드분석
- 스프링MVC
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |